

Oyes una canción familiar en el club o en el restaurante. Has escuchado esta canción miles de veces desde hace mucho tiempo y el sentimentalismo de la canción realmente toca tu corazón. ¡Desesperadamente la quieres volver a escuchar en la mañana, pero no recuerdas su nombre!.
Afortunadamente, en nuestro increíble mundo futurista, tienes un teléfono con software de reconocimiento de música instalado. Puedes relajarte, ya que el Software te dijo el nombre de la canción, así que sabes que la puedes escuchar una y otra vez hasta que se convierta en una parte de ti…o te llegue a desesperar…
Mobile technologies, junto con el inmenso progreso del procesamiento de la señal de audio, nos han dado, algorithm developers, la habilidad de crear reconocedores de música. Una de las más populares aplicaciones de reconocimiento de música es Shazam. Captura en 20 segundos una canción, sin importar si es la intro, el verso, o el coro, la aplicación creará una huella digital de la muestra grabada, consultará la base de datos, y utilizará su algoritmo de reconocimiento de música para decirte exactamente cual es la canción que estás escuchando.
¿Como funciona Shazam realmente? Shazam’s algorithm La aplicación fue expuesta por primera vez por su inventor Avery Li-Chung Wang en el 2003. En este artículo hablaremos de los fundamentos del algoritmo de reconocimiento de música Shazam.
De Analógico a Digital – Una Señal de Muestreo
¿Qué es realmente el sonido? Es algún tipo de material místico que no podemos tocar pero que vuela en nuestros oídos y nos hace escuchar las cosas?
Por supuesto, este no es el caso. Sabemos que, en realidad, el sonido es una vibración que se propaga como una mechanical wave ola mecánica de presión y se desplaza a través de un medio tal como el aire o el agua. Cuando esta vibración llega a nuestros oídos, particularmente en el tímpano, mueve pequeños huesos que transmiten las vibraciones a las células ciliadas bastante profundas en nuestro oído interno. Además, las pocas células ciliadas producen impulsos eléctricos que se transmiten a nuestro cerebro a través del nervio auditivo del oído.
Los dispositivos de grabación imitan este proceso mediante la presión de la onda de sonido para convertirla en una señal eléctrica. Una onda de sonido real en el aire es una continuos señal de presión. En un micrófono, el primer componente eléctrico al encontrar esta señal se traduce en una señal de tensión analógica – nuevamente, continua. Esta señal continua no es tan útil en el mundo digital, así que antes de ser procesada, debe ser traducida en discrete signal una señal discreta que se pueda almacenar digitalmente. Esto se realiza mediante la captura de un valor digital que representa la amplitud de la señal.
La conversión implica quantization la cuantificación de la entrada que necesariamente introduce una pequeña cantidad de error. Por lo tanto, en lugar de una simple conversión, un analog-to-digital converter convertidor analógico digital realiza muchas conversiones en pedazos muy pequeños de la señal – un proceso conocido como sampling.

El Nyquist-Shannon Theorem teorema de Nyquist –Shannon nos dice qué tasa de muestreo es necesaria para capturar una determinada frecuencia en una señal continua. En particular, para captar todas las frecuencias que un ser humano pueda oír en una señal de audio, debemos muestrear la señal a una frecuencia doble que la del rango auditivo humano. El oído humano puede detectar frecuencias aproximadamente entre 20 Hz y 20.000 Hz. Como resultado, la mayoría de las veces el audio grabado tiene una velocidad de muestreo de 44.100 Hz. Esta es la frecuencia de muestreo de Compact Discs discos compactos y también es la más utilizada con MPEG-1audio (VCD,SVCD, MP3). Este índice específico fue elegido inicialmente por Sony, porque podía ser grabado en el equipo de vídeo modificado funcionando a una velocidad de 25 fotogramas por segundo (PAL) o 30 fotogramas por segundo (usando un NTSC grabador de vídeo monocromo) y cubriendo los 20.000 Hz de ancho de banda necesarios para coincidir con el pensamiento profesional de los equipos de grabación analógica). Así que a la hora de elegir la frecuencia de la muestra que se necesita para ser grabada probablemente querrás escoger ir con 44,100 Hz.
Grabando – Capturando el Sonido
Grabar una señal de audio muestreado es fácil. Ya que las tarjetas de sonido modernas ya vienen con convertidores analógicos-digitales, sólo tienes que seleccionar un lenguaje de programación, encontrar una biblioteca adecuada y establecer la frecuencia de la muestra, el número de canales (mono o estéreo) y normalmente, el tamaño de la muestra (por ej. Muestras de 16 bits). Después abre la línea de tu tarjeta de sonido, al igual que cualquier flujo de entrada, y escribe en una matriz de bytes. Así es cómo puedes hacerla en Java:
private AudioFormat getFormat() { float sampleRate = 44100; int sampleSizeInBits = 16; int channels = 1; //mono boolean signed = true; //Indicates whether the data is signed or unsigned boolean bigEndian = true; //Indicates whether the audio data is stored in big-endian or little-endian order return new AudioFormat(sampleRate, sampleSizeInBits, channels, signed, bigEndian); } final AudioFormat format = getFormat(); //Fill AudioFormat with the settings DataLine.Info info = new DataLine.Info(TargetDataLine.class, format); final TargetDataLine line = (TargetDataLine) AudioSystem.getLine(info); line.open(format); line.start();Lee los datos de ‘TargetDataLine’. (En este ejemplo, el ‘Running’ es una variable global que está detenida por otro subproceso – por ejemplo, si tenemos GUI con el botón STOP).
OutputStream out = new ByteArrayOutputStream(); running = true; try { while (running) { int count = line.read(buffer, 0, buffer.length); if (count > 0) { out.write(buffer, 0, count); } } out.close(); } catch (IOException e) { System.err.println("I/O problems: " + e); System.exit(-1); }Dominio de Tiempo y Dominio de Frecuencia
Lo que tenemos en esta matriz de bytes es la señal grabada en el tiempo del dominio domain. La señal de dominio de tiempo representa el cambio de amplitud de la señal a lo largo del tiempo.
En las primeras décadas del siglo XIX, Jean-Baptiste Joseph Fourier hizo el notable descubrimiento que ninguna señal en el dominio del tiempo es equivalente a la suma de algunos (posiblemente infinito) números de simples señales sinusoidal, dado que cada componente tiene una cierta sinusoidal de frecuencia, amplitud y fase. La serie de los sinusoides que juntos forman la señal de dominio de tiempo original se conoce como serie de Fourier.
En otras palabras, es posible representar cualquier señal en el dominio del tiempo simplemente dando el conjunto de frecuencias, amplitudes y fases correspondientes a cada sinusoide que compone la señal. Esta representación de la señal es conocida como la frecuencia de dominio frequency domain. En cierto modo, el dominio de la frecuencia actúa como un tipo de huella dactilar o firma para la señal de dominio de tiempo, proporcionando una representación estática de una señal dinámica.
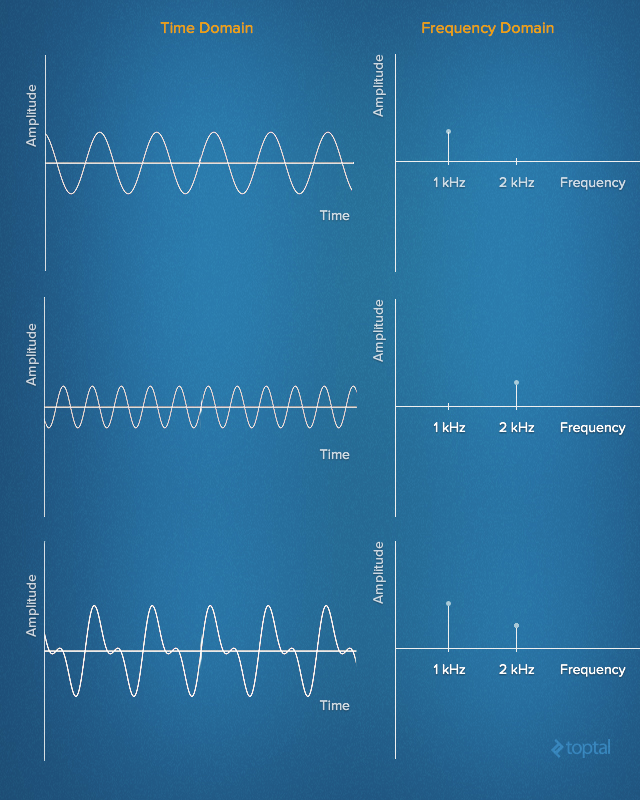
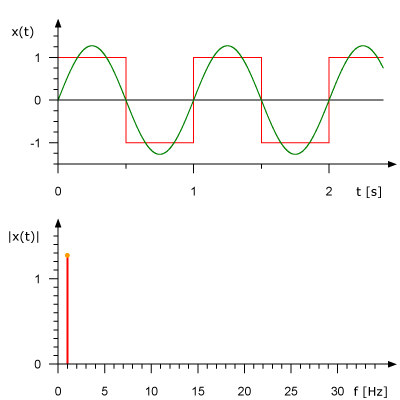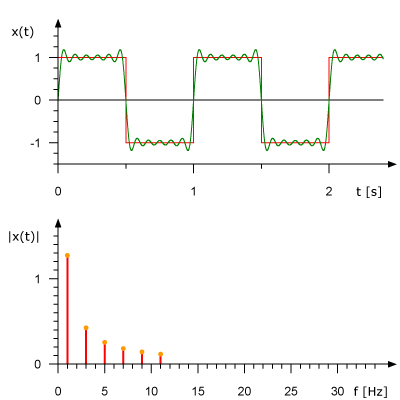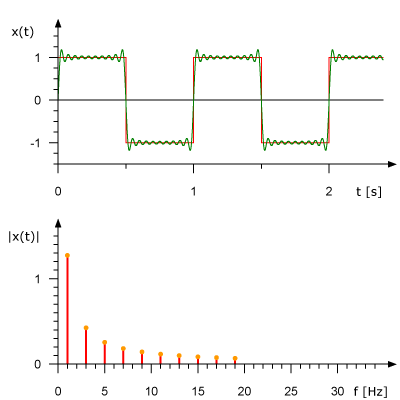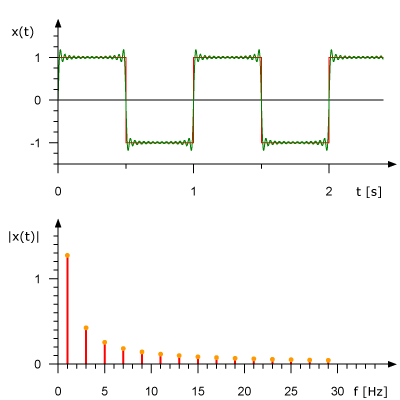
La siguiente animación muestra la serie de Fourier de una onda cuadrada de 1 HZ squarewave y cómo una onda cuadrada (aproximada) puede ser generada a partir de componentes sinusoidales. La señal se muestra en el dominio del tiempo anterior y en el dominio de la frecuencia a continuación.
Analizar una señal en el dominio de la frecuencia simplifica muchas cosas inmensamente. Es más cómodo en el mundo del procesamiento de señal digital porque el ingeniero puede estudiar el espectro (la representación de la señal en el dominio de la frecuencia) y determinar las frecuencias que están presentes y las que faltan. Después de eso, uno puede hacer el filtrado, aumentar o disminuir algunas frecuencias, o simplemente reconocer el tono exacto de las frecuencias.
La transformada discreta de Fourier
Por lo tanto, necesitamos encontrar una manera de convertir nuestra señal desde el momento de dominio para el dominio de la frecuencia. Aquí lo llamamos la transformación discreta de Fourie Discrete Fourier Transform(DFT) ara ayudar. La DFT es un método matemático para realizar Análisis de Fourier en un discreto (muestra) de la señal. Convierte una lista finita de muestras equidistantes de una función en la lista de los coeficientes de una combinación finita de complejas sinusoides, ordenadas por sus frecuencias, considerando si las sinusoides habían sido muestreadas en la misma proporción.
Uno de los algoritmos numéricos más populares para el cálculo de la DFT es la Fast Fourier transform (FFT). El más utilizado es la variación de FFT Cooley–Tukey algorithm. Este algoritmo es del tipo divide-y-vencerás que recursivamente divide una DFT en varias y pequeñas DFTs. Mientras que la evaluación de un DFT requiere directamente O(n2) operations, with a Cooley-Tukey FFT el mismo se computa en iO(n log n) operations.
No es difícil encontrar una biblioteca adecuada para la FFT. Aquí están algunos de ellos:
- C– FFTW
- C++– EigenFFT
- Java– JTransform
- Python– NumPy
- Ruby– Ruby-FFTW3 (Interface to FFTW)
A continuación se muestra un ejemplo de una función FFT escrita en Java. (FFT tiene números complejos como entrada. Para entender la relación entre números complejos y funciones trigonométricas, lee acerca de Euler’s formula.)
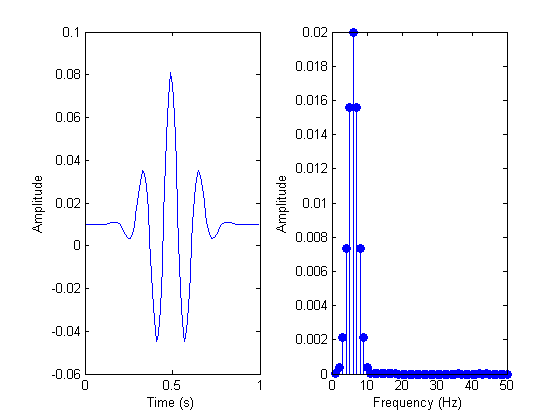
public static Complex[] fft(Complex[] x) { int N = x.length; // fft of even terms Complex[] even = new Complex[N / 2]; for (int k = 0; k < N / 2; k++) { even[k] = x[2 * k]; } Complex[] q = fft(even); // fft of odd terms Complex[] odd = even; // reuse the array for (int k = 0; k < N / 2; k++) { odd[k] = x[2 * k + 1]; } Complex[] r = fft(odd); // combine Complex[] y = new Complex[N]; for (int k = 0; k < N / 2; k++) { double kth = -2 * k * Math.PI / N; Complex wk = new Complex(Math.cos(kth), Math.sin(kth)); y[k] = q[k].plus(wk.times(r[k])); y[k + N / 2] = q[k].minus(wk.times(r[k])); } return y; }Y aquí está un ejemplo de una señal antes y después del análisis FFT:
Reconocimiento de Música: Las Huellas Digitales en una Canción
Un desafortunado efecto colateral de FFT es que perdemos una gran cantidad de información acerca de la sincronización (aunque teóricamente esto puede ser evitado, el rendimiento de gastos generales es enorme) para una canción de 3 minutos, podemos ver todas las frecuencias y sus magnitudes, pero no tenemos una pista cuando aparecieron en la canción. ¡Pero esta es la clave de la información que hace que la canción sea así! De alguna manera tenemos que saber en qué momento cada frecuencia apareció.
Es por eso que introducimos el tipo de ventana deslizante, o fragmento de datos así como la transformación de esta parte de la información. El tamaño de cada fragmento puede determinarse de distintas formas. Por ejemplo, si queremos grabar el sonido en estéreo, con muestras de 16 bits, a 44.100 Hz, un segundo de ese sonido será de 44.100 muestras * 2 bytes * 2 canales ≈ 176 kB. Si cogemos 4 kB para el tamaño de un segmento, tendremos 44 porciones de datos para analizar en cada segundo de la canción. Esa es una buena densidad suficiente para el análisis detallado.
Ahora volvamos a la programación:
byte audio [] = out.toByteArray() int totalSize = audio.length int sampledChunkSize = totalSize/chunkSize; Complex[][] result = ComplexMatrix[sampledChunkSize][]; for(int j = 0;i < sampledChunkSize; j++) { Complex[chunkSize] complexArray; for(int i = 0; i < chunkSize; i++) { complexArray[i] = Complex(audio[(j*chunkSize)+i], 0); } result[j] = FFT.fft(complexArray); } En el bucle interior estamos poniendo los datos de dominio de tiempo (las muestras) en un número complejo con parte imaginaria 0. En el bucle exterior, nos iteramos a través de todos los segmentos y realizamos un análisis FFT de cada uno.Una vez que tengamos la información acerca de la frecuencia de la señal, podemos empezar a formar nuestra huella digital de la canción. Esta es la parte más importante de todo el proceso de reconocimiento de música de Shazam. El principal desafío es cómo distinguir, en el océano de las frecuencias capturadas, las frecuencias que son las más importantes. Intuitivamente, podemos buscar las frecuencias con mayor magnitud (comúnmente llamadas picos).
Sin embargo, en una canción de la gama de frecuencias fuerte puede variar entre baja C – C1 (32,70 Hz) y alta C – C8 (4,186.01 Hz). Este es un gran intervalo en cubierta. Así que en lugar de analizar toda la gama de frecuencias a la vez, podemos elegir varios intervalos más pequeños. Elige en base a las frecuencias comunes de componentes musicales importantes y analiza cada uno por separado. Por ejemplo, podríamos utilizar los intervalos este chico eligió para su implementación del algoritmo de Shazam. Estos son los 30 Hz – 40 Hz, 40 Hz – 80 Hz y 80 Hz – 120 Hz para los tonos bajos (cubriendo bass guitar, por ejemplo), y 120 Hz – 180 Hz y 180 Hz – 300 Hz para el oriente y los tonos más altos (que cubre la mayoría de los demás instrumentos y voces).
Ahora, dentro de cada intervalo podemos determinar la frecuencia con la mayor magnitud. Esta información constituye una firma para esta parte de la canción y esta firma se convierte en parte de la huella digital de la canción como un todo.
public final int[] RANGE = new int[] { 40, 80, 120, 180, 300 }; // find out in which range is frequency public int getIndex(int freq) { int i = 0; while (RANGE[i] < freq) i++; return i; } // result is complex matrix obtained in previous step for (int t = 0; t < result.length; t++) { for (int freq = 40; freq < 300 ; freq++) { // Get the magnitude: double mag = Math.log(results[t][freq].abs() + 1); // Find out which range we are in: int index = getIndex(freq); // Save the highest magnitude and corresponding frequency: if (mag > highscores[t][index]) { points[t][index] = freq; } } // form hash tag long h = hash(points[t][0], points[t][1], points[t][2], points[t][3]); } private static final int FUZ_FACTOR = 2; private long hash(long p1, long p2, long p3, long p4) { return (p4 - (p4 % FUZ_FACTOR)) * 100000000 + (p3 - (p3 % FUZ_FACTOR)) * 100000 + (p2 - (p2 % FUZ_FACTOR)) * 100 + (p1 - (p1 % FUZ_FACTOR)); }Ten en cuenta que debemos asumir que la grabación no está hecha en perfectas condiciones (por ejemplo, una “sala de sordos”) y como resultado se debe incluir un factor de aproximación. Un análisis del factor de aproximación debe ser tomado en serio y en un sistema real, el programa debe tener una opción para establecer este parámetro en función a las condiciones de la grabación.
Para facilitar la búsqueda, esta firma se convierte en la clave en una tabla de hashtag. El valor correspondiente es el tiempo en el que este conjunto de frecuencias apareció en la canción, junto con el ID de la canción (título de la canción y del artista). Aquí está un ejemplo de cómo pueden aparecer estos registros en la base de datos.
| Hash Tag | Time in Seconds | Song |
| 30 51 99 121 195 | 53.52 | Song A by artist A |
| 33 56 92 151 185 | 12.32 | Song B by artist B |
| 39 26 89 141 251 | 15.34 | Song C by artist C |
| 32 67 100 128 270 | 78.43 | Song D by artist D |
| 30 51 99 121 195 | 10.89 | Song E by artist E |
| 34 57 95 111 200 | 54.52 | Song A by artist A |
| 34 41 93 161 202 | 11.89 | Song E by artist E |
Si ejecutamos toda una biblioteca de canciones a través de este proceso, podemos construir una base de datos completa con una huella digital de cada canción en la biblioteca.
Eligiendo una Canción
Para identificar una canción que se está reproduciendo actualmente en el club, graba la canción en tu teléfono y ejecuta la grabación mediante el mismo proceso de rastreo digital como se hizo anteriormente. Entonces puedes iniciar la búsqueda coincidente en la base de datos de hashtags.
Como sucede, muchos de los hashtags corresponden a varias canciones. Por ejemplo, puede ser que alguna pieza de una canción suena exactamente como algún fragmento de canción E. Por supuesto, esto no es sorprendente – los músicos siempre han “prestado” letras de canciones unos de otros y, en estos días, los productores muestran otras canciones todo el tiempo. Cada vez que hemos partido de un hashtag, el número de coincidencias posibles se hace más pequeño, pero es probable que esta información por sí sola no va a reducir el partido a una sola canción. Así que hay una cosa más que tenemos que verificar con nuestro algoritmo de reconocimiento de música, y esa es la distribución.
La muestra que se registró en el club puede ser cualquier punto de la canción, así que simplemente no podemos coincidir con el Timestamp del hashtag coincidente con la marca de nuestra muestra. Sin embargo, con varios algoritmos de hashtags que coinciden, podemos analizar el tiempo relativo de la combinación, y por tanto, aumentar nuestra seguridad.
Por ejemplo, si buscas en la tabla de arriba, verás que el hashtag ‘30 51 99 121 195” corresponde a tanto la canción A, como canción E. Si un segundo más tarde hacemos coincidir el hash ‘34 57 95 111 200”, que es más una coincidencia para una canción, pero en este caso sabemos que tanto los hashes coinciden y las diferencias horarias también.
// Class that represents specific moment in a song private class DataPoint { private int time; private int songId; public DataPoint(int songId, int time) { this.songId = songId; this.time = time; } public int getTime() { return time; } public int getSongId() { return songId; } }Let’s take i1 and i2 as moments in the recorded song, and j1 and j2 as moments in the song from database. We can say that we have two matches with time difference match if:
RecordedHash(i1) = SongInDBHash(j1) AND RecordedHash(i2) = SongInDBHash(j2)
AND
abs(i1 – i2) = abs (j1 – j2)
Esto nos da flexibilidad para grabar la canción desde el principio, mitad o final.
Por último, es poco probable que cada momento de la canción que registramos en el club coincidirá con cada momento correspondiente de la misma canción en nuestra biblioteca, la cual grabamos en el estudio. La grabación incluye un montón de ruido que introducirá algunos errores en los partidos. Así que en lugar de tratar de eliminar todo pero la canción correcta de nuestra lista de partidos, al final, hemos conciliado ordenar todas las canciones en orden descendente de probabilidad, y nuestra favorita es la primera canción en la lista de clasificación.
De Abajo para Arriba
He aquí un resumen de todo el proceso de conciliación y de reconocimiento de música, de arriba a abajo:
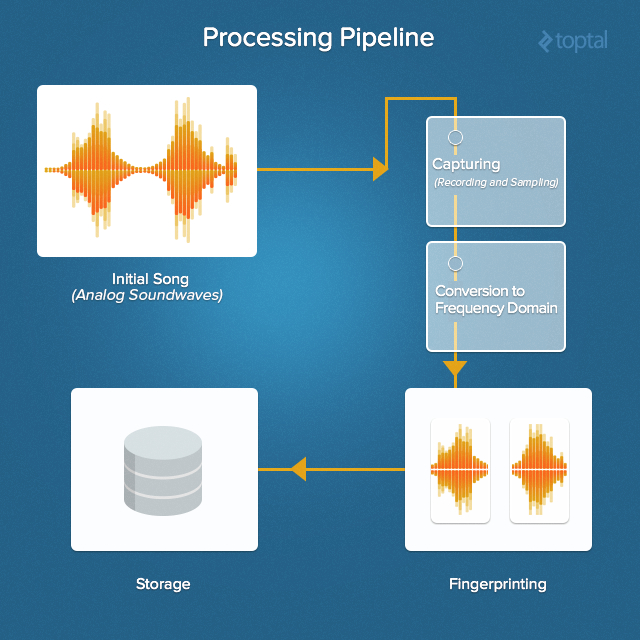
Para este tipo de sistema, la base de datos puede llegar a ser bastante grande, así que es importante utilizar algún tipo de base de datos cambiante. No hay ninguna necesidad especial de relaciones, y el modelo de datos termina siendo bastante simple, así que es un buen caso para el uso de algún tipo de base de datos NoSQL.
¡Conclusión, Shazam!
Este tipo de software de reconocimiento de música puede ser utilizado para encontrar las similitudes entre las canciones. Ahora que entiendes cómo funciona Shazam, puedes ver cómo esto puede tener aplicaciones más allá de la simple Shazaming que esa nostálgica canción que suena en el radio del taxi. Por ejemplo, puedes ayudar a identificar el plagio en la música, o para averiguar quién fue la inspiración inicial para algunos pioneros del blues, jazz, rock, pop, o cualquier otro género. Quizá un buen experimento sería para llenar la base de datos con la música clásica de Bach, Beethoven, Vivaldi, Wagner, Chopin y Mozart y trata de encontrar las similitudes entre las canciones. ¡Pensaría que incluso Bob Dylan, Elvis Presley y Robert Johnson fueron plagiadores!
Pero todavía no podemos condenarlos, porque la música es simplemente una ola que oímos, memorizamos y repetimos en nuestras cabezas, donde evoluciona y cambia hasta que grabamos en el estudio y lo pasamos al siguiente gran genio musical.
Artículo via Toptal


