

El Aprendizaje de Máquina (AM) está formando su propio nombre, con un reconocimiento en crecimiento que muestra que AM puede jugar un papel importante dentro de una gran gama de aplicaciones cruciales, como lo son minería de datos, procesador de idioma natural, reconocimiento de imagen y sistemas de expertos. AM provee posibles soluciones en todos estos dominios y más. Además está creada para ser un pilar de nuestra civilización futura.
El suplemento de diseñadores con habilidad AM no llega todavía a la demanda. Una gran parte de esto es porque AM es simplemente complicado. Este tutorial introduce lo básico de la teoría de Aprendizaje de Máquina, explicando los temas comunes y conceptos haciendo más fácil de seguir la lógica y encontrar la comodidad con el tema.

¿Qué Es El Aprendizaje De Máquina?
¿Entonces, qué es exactamente “Aprendizaje de Máquina”? AM es de hecho muchas cosas. El campo es muy vasto y se está expandiendo rápidamente y continuamente está siendo particionado y sub-particionado sin descanso, en sub-especialidades y tipos de aprendizaje de máquina.
Sin embargo, hay un denominador común básico y el tema dominador se resume mejor con esta declaración frecuentemente citada, hecha por Arthur Samuel en 1959: “[Aprendizaje de máquina es el] campo de estudio que da a las computadoras la habilidad de aprender sin ser programadas explícitamente.”
Y más recientemente, en 1997, Tom Mitchell dio una definición “bien planteada” que ha demostrado ser más útil para los tipos de ingeniería: “Se dice que un programa de computadora aprende de experiencia E, con respecto a alguna tarea T y alguna medida de desempeño P, mejora con experiencia E.”
Así que si quieres que tu programa prediga, por ejemplo, patrones de tráfico en una intersección ocupada (prueba T), lo puedes arruinar usando un algoritmo de aprendizaje de máquina, con data sobre patrones de tráfico antiguo (experiencia E) y, si lo ha “aprendido” exitosamente, hará un mejor trabajo al predecir futuros patrones de tráfico (Medida de desempeño P).
La altamente compleja naturaleza de muchos problemas de la vida real, comúnmente significa que inventar algoritmos especializados que los resolverían perfectamente todo el tiempo, no es práctico y hasta imposible. Algunos ejemplos de problemas en el aprendizaje de máquina incluyen, “¿Esto es cáncer?”, “¿Cuál es el valor de mercado de esta casa?”, “¿Cuál de estas personas son buenos amigos?”, “¿Explotará este motor de cohete en el despegue?”, “¿Le gustará esta película a esta persona?”, “¿Quién es él/ella?”, “¿Qué dijiste?”, y “¿Cómo se vuela esto?”. Todos estos problemas son un excelente foco para un proyecto AM, y de hecho, AM ha sido aplicado a cada uno con gran éxito.
Entre los diferentes tipos de tarea AM, se traza una distinción crucial entre aprendizaje supervisado y no supervisado:
- Aprendizaje de máquina supervisado: El programa está “entrenado” en un set pre-definido de “ejemplos de entrenamiento”, lo cual después facilitó su habilidad de alcanzar una conclusión acertada cuando se le pasa nueva data.
- Aprendizaje de Máquina no supervisado: Al programa se le da una cantidad de data y debe encontrar patrones y relaciones dentro de éste.
Primeramente, nos vamos a enfocar en aprendizaje supervisado pero el final del artículo incluye una discusión breve sobre aprendizaje no supervisado, con algunos links para aquellos interesados en continuar en el tema.
Aprendizaje de Máquina Supervisado
En la mayoría de las aplicaciones del aprendizaje supervisado, lo que se quiere lograr es crear una función de predicción bien perfeccionada h(x) (a veces llamada la “hipótesis”). “Aprender” consiste en usar algoritmos matemáticos para optimizar esta función para que, al darle data x sobre cierto dominio (digamos, pies cuadrados de una casa), hará una predicción precisa de un valor interesante h(x) (digamos, precio de mercado para dicha casa).
En práctica, x casi siempre representa múltiples puntos de data. Así que, por ejemplo, un pronosticador de precios de casas podría no solo tomar pies cuadrados (x1) pero también cantidad de cuartos (x2), cantidad de baños (x3), cantidad de pisos (x4), años de construcción (x5), código postal (x6), y así sucesivamente. Determinar cuáles entradas usar es parte importante del diseño AM. Sin embargo, por el bien de la explicación, es más fácil asumir que se usa solo un valor de entrada.
Digamos que nuestro pronosticador simple tiene esta forma:
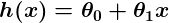
donde 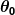 y
y 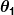 son constantes. Nuestra meta es encontrar los valores perfectos de y hacer que nuestro pronosticador funcione lo mejor posible.
son constantes. Nuestra meta es encontrar los valores perfectos de y hacer que nuestro pronosticador funcione lo mejor posible.
Optimizar el pronosticador h(x) ya no usa ejemplo de entrenamiento. Por cada ejemplo de entrenamiento, tenemos un valor de entrada x_train, por el que se conoce previamente una salida correspondiente, y. Por cada ejemplo, encontramos la diferencia entre el valor correcto conocido y, y nuestro valor pronosticado h(x_train). Con suficientes ejemplos de entrenamiento, estas diferencias nos dan una manera útil de medir lo “errado” de h(x). Después podemos modificar un poco h(x) al alterar los valores de y para hacerlo “menos errado”. Este proceso se repite una y otra vez hasta que el sistema ha unido los mejores valores para y . De esta manera, el pronosticador pasa a ser entrenado y está listo para hacer predicciones de la vida real.
Un Ejemplo Simple de Aprendizaje de Máquina
En este post, mantenemos los problemas simples por el bien de la ilustración, pero la razón por la que AM existe es porque, en la vida real, los problemas son mucho más complejos. En esta pantalla plana podemos hacer un dibujo de, máximo, un set de data tridimensional pero los problemas AM comúnmente tratan con data con millones de dimensiones y funciones de predicción muy complejas. AM resuelve problemas que no pueden ser resueltos a través de medios numéricos únicamente.
Con eso en mente, veamos un ejemplo simple. Digamos que tenemos la siguiente data de entrenamiento, donde los empleados de la compañía han calificado su satisfacción en escala del 1 al 100:
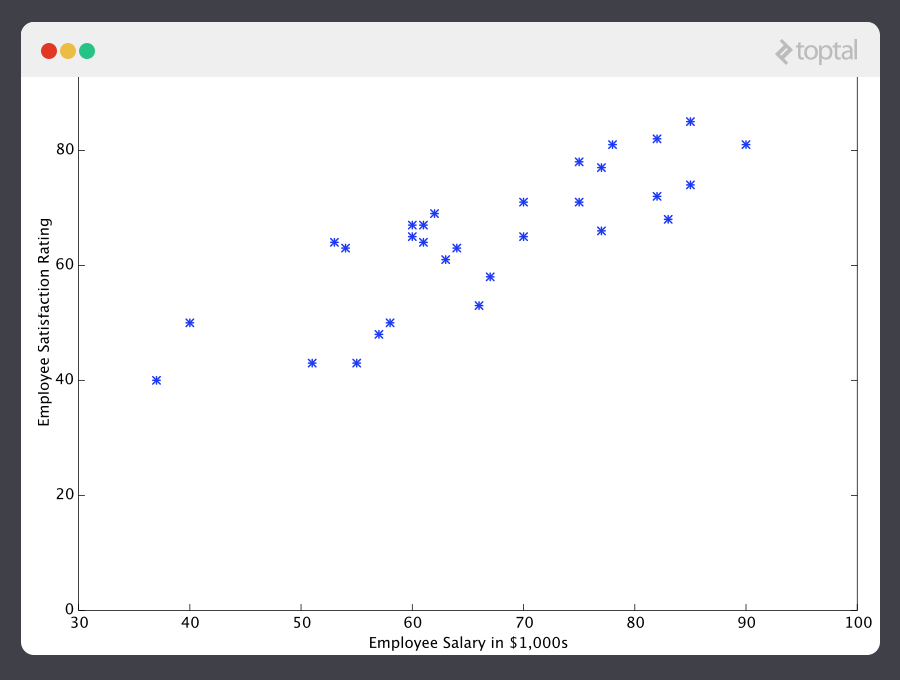
Primero, puedes ver que los datos son algo ruidosos. Esto se debe a que a pesar de que podemos ver que hay un patrón (la satisfacción de los empleados tiende a subir a medida que sube el salario), no todo encaja en una línea recta. Este siempre va a ser el caso con datos reales (¡y definitivamente queremos entrenar nuestra máquina con datos reales!). Entonces, ¿cómo podemos entrenar una máquina para que prediga a la perfección el nivel de satisfacción de un empleado? La verdad es que no podemos. La meta del AM no es adivinar a la “perfección”, debido a que el AM se ocupa de dominios donde no existe tal cosa. La meta es hacer predicciones que sean lo suficientemente buenas para ser útiles.
Aquí podemos recordar la famosa declaración del Matemático y Profesor de Estadísticas Británico George E. P. Box que dice “todos los modelos están mal pero algunos son útiles”.
La meta del AM no es adivinar a la “perfección”, debido a que el AM se ocupa de dominios donde no existe tal cosa. La meta es hacer predicciones que sean lo suficientemente buenas para ser útiles.
El AM se basa fuertemente en estadísticas. Por ejemplo, cuando entrenamos a nuestra máquina para que aprenda tenemos que darle una muestra aleatoria estadísticamente significativa como datos de entrenamiento. Si el set de entrenamiento no es aleatorio, existe la posibilidad de que la máquina aprenda patrones que en realidad no están en la muestra. Y si el set de entrenamiento es muy pequeño (lee la ley de los grandes números), no sabremos mucho y puede ser que se obtengan resultados inconclusos. Por ejemplo si intentamos predecir patrones de satisfacción de toda una compañía recolectando datos solamente de los gerentes, probablemente tendríamos muchos errores.
Sabiendo esto, ahora le daremos a nuestra máquina los datos que nos dieron arriba para que los aprenda. Primero tenemos que inicializar nuestro predictor h(x) con valores razonables de and . Ahora nuestro predictor se verá así cuando este en el set de entrenamiento:
Si le preguntamos a este predictor por la satisfacción de un empleado que gane $60k, mostraría un índice de 27:
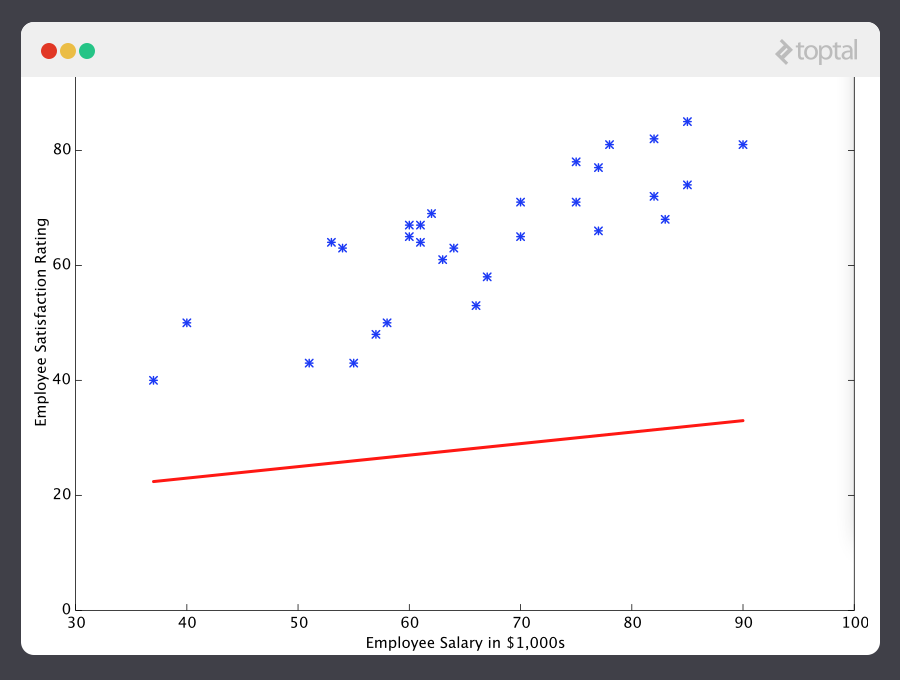
Obviamente se puede ver que esta una predicción muy mala y esta máquina aún no sabe mucho.
Ahora démosle a este predictor todos los sueldos de nuestro set de entrenamiento, luego compararemos las diferencias entre los resultados de satisfacción predichos y los índices de satisfacción reales de los empleados correspondientes. Si hacemos un poco de magia matemática (la cual explicaré a continuación) podemos calcular, con gran certeza, los valores de 13.12 de y 0.61 para nos daría una mejor predicción.
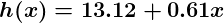
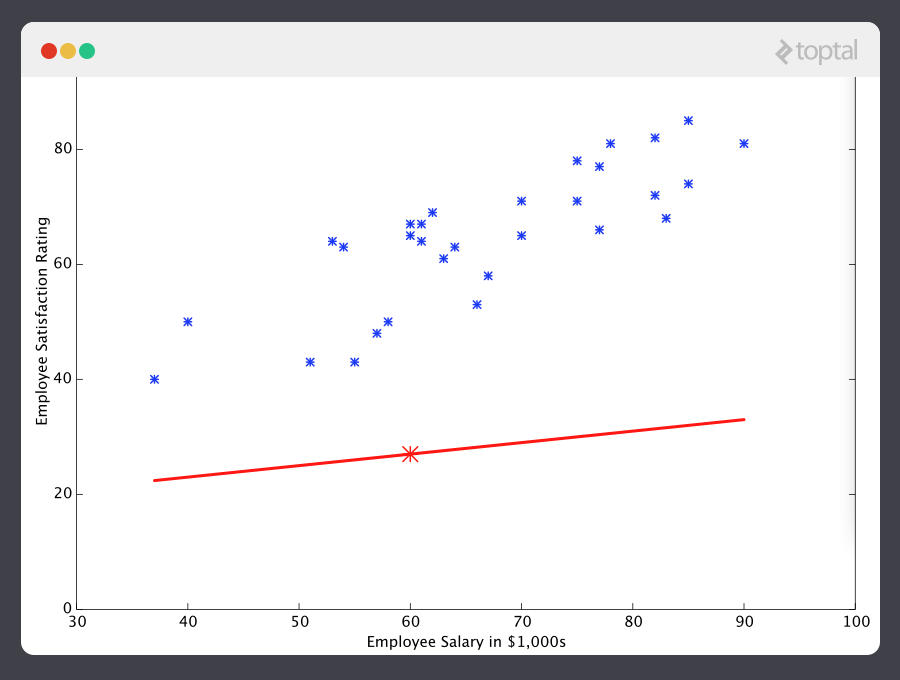
Si repetimos este proceso, por ejemplo unas 1500 veces, nuestro predictor terminará viéndose así:
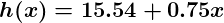
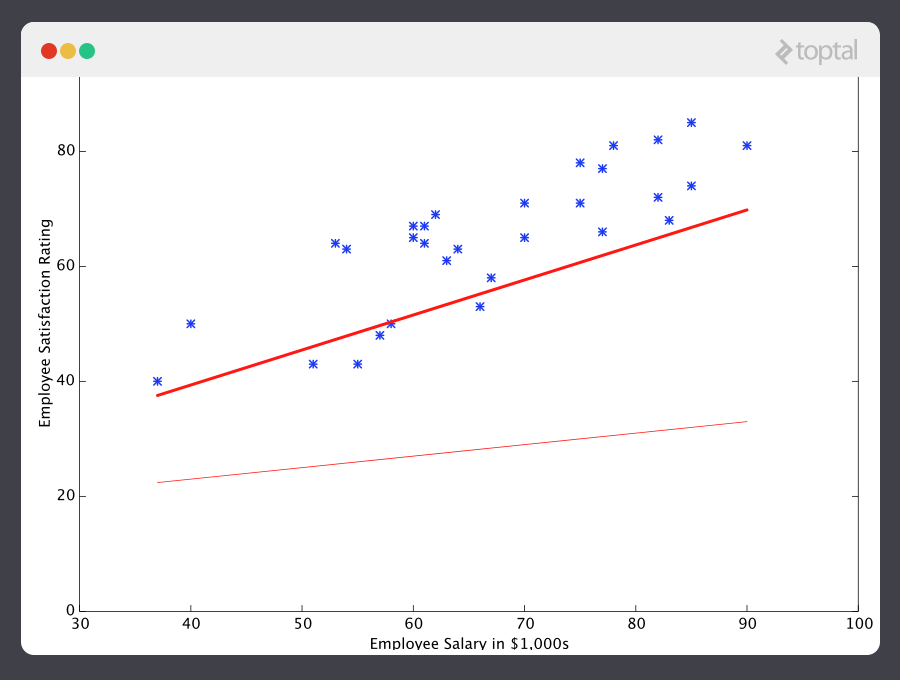
A estas alturas si repetimos el proceso encontraremos que y no hay cambio de ninguna cantidad estimable y por eso vemos que el sistema ha convergido. Si no nos hemos equivocado, eso significa que encontramos el predictor más óptimo. Ahora, si le preguntamos nuevamente a la máquina por el índice de satisfacción del empleado que gana $60k, hará una predicción de un índice de más o menos 60.
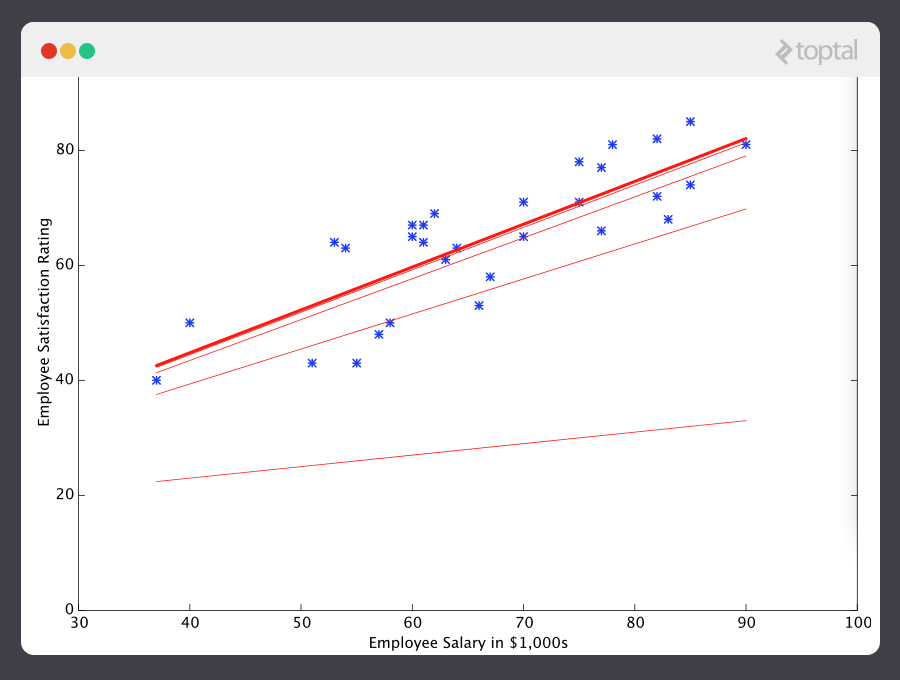
Ahora sí estamos yendo a algún lado.
Nota Sobre Complejidad
El ejemplo de antes es técnicamente un problema sencillo de regresión lineal univariante, el cual puede ser resuelto al derivar una ecuación sencilla y así nos saltaríamos todo el proceso de “afinación”. Aun así piensa por un momento en un predictor que se viera así:
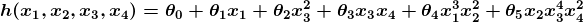
Esta función toma datos de entrada en cuatro dimensiones y tiene una variedad de términos polinómicos. Derivar una ecuación normal para esta función es un gran reto. Muchos problemas de aprendizaje de máquina modernos toman en cuenta miles e incluso millones de dimensiones de datos para crear predicciones usando cientos de coeficientes. Predecir cómo se expresará el genoma de un organismo o cómo será el clima dentro de 50 años son algunos ejemplos de estos problemas complejos.
Por suerte, el enfoque iterativo que toman los sistemas AM es mucho más resistente cuando se trata de tales complejidades. En lugar de usar fuerza bruta, un sistema de aprendizaje de máquina “siente todo” hasta encontrar la respuesta. Para grandes problemas esto funciona mucho mejor. Aunque esto no significa que el AM puede resolver cualquier problema complejo arbitrario (no puede), sí significa que es una herramienta muy eficaz y flexible.
Descendencia de Gradiente – Minimizando las “Equivocaciones”
Veamos con detenimiento cómo funciona este proceso iterativo. En el ejemplo de arriba, ¿cómo nos aseguramos que y están mejorando y no empeorando? La respuesta está en nuestra “medición de equivocación”, la cual ya hemos mencionado, junto a un pequeño cálculo.
La medición de equivocación se define como función de costo (es decir, función de pérdida), 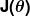 . La entrada
. La entrada  representa todos los coeficientes que usamos en el predictor. En este caso, es en realidad el par y .
representa todos los coeficientes que usamos en el predictor. En este caso, es en realidad el par y . 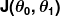 esto nos da una medición matemática de lo equivocado que esta nuestro predictor cuando se usa los valores dados de y .
esto nos da una medición matemática de lo equivocado que esta nuestro predictor cuando se usa los valores dados de y .
La opción de función de costos es otra pieza importante de un programa de AM. En diferentes contextos, “equivocarse” puede significar diferentes cosas. En nuestro ejemplo de satisfacción de empleado el estándar establecido es la función de mínimos cuadrados:
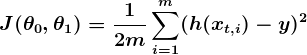
Con los mínimos cuadrados, la penalización por una mala suposición sube cuadráticamente entre la suposición y la respuesta correcta, por lo que actúa como una medición de equivocación muy “estricta”. La función de costo almacena una penalidad promedio de todos los ejemplos de entrenamiento.
Nuestra meta es encontrar y para nuestro predictor h(x) y que nuestra función de costo sea lo más pequeña posible. Para lograrlo recurrimos al poder de cálculo.
Considera la siguiente gráfica de una función de costo para un problema particular de AM:
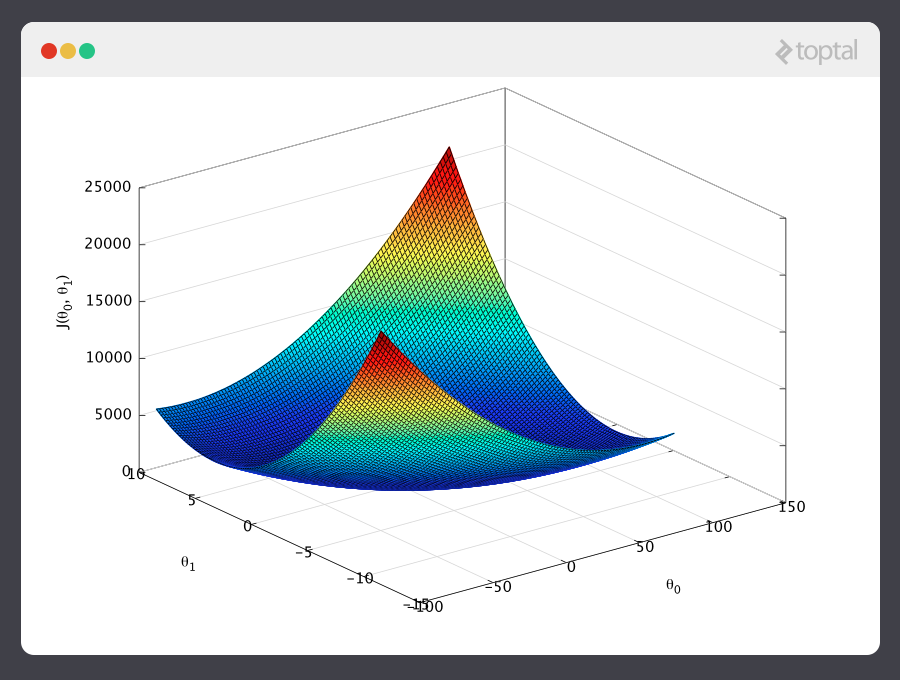
Aquí podemos ver el costo asociado a los valores de y . Podemos ver que la gráfica tiene una ligera forma de tazón. El fondo del tazón representa el costo más bajo que nuestro predictor puede calcular basado en los datos de entrenamiento proporcionados. La meta es “bajar por la colina” y encontrar y correspondiente a este punto.
Aquí es donde entra el cálculo en este tutorial de aprendizaje de máquina. Para mantener la explicación sencilla, no voy a escribir las ecuaciones pero básicamente lo que hacemos es tomar el gradiente de , que es el par de derivadas de (uno sobre y uno sobre ). El gradiente será diferente para cada valor diferente de y , y nos dice cual es “la pendiente de la colina” y en particular, “hacia donde es abajo”, para este particular s. Por ejemplo cuando introducimos nuestros valores actuales de en el gradiente, podría decirnos que agregar un poco de y restándole un poco de nos llevará en dirección al piso de la función de costo. Por lo que añadimos un poco a , y restamos un poco de , y ¡voilà! Hemos terminando una parte de nuestro algoritmo de aprendizaje. Nuestro predictor actualizado, h(x) = + x, nos dará mejores predicciones que antes. Nuestra máquina es un poco más inteligente ahora.
Este proceso de alternar entre calcular el gradiente actual y actualizar el s de los resultados es conocido como descendencia de gradiente o gradient descent.

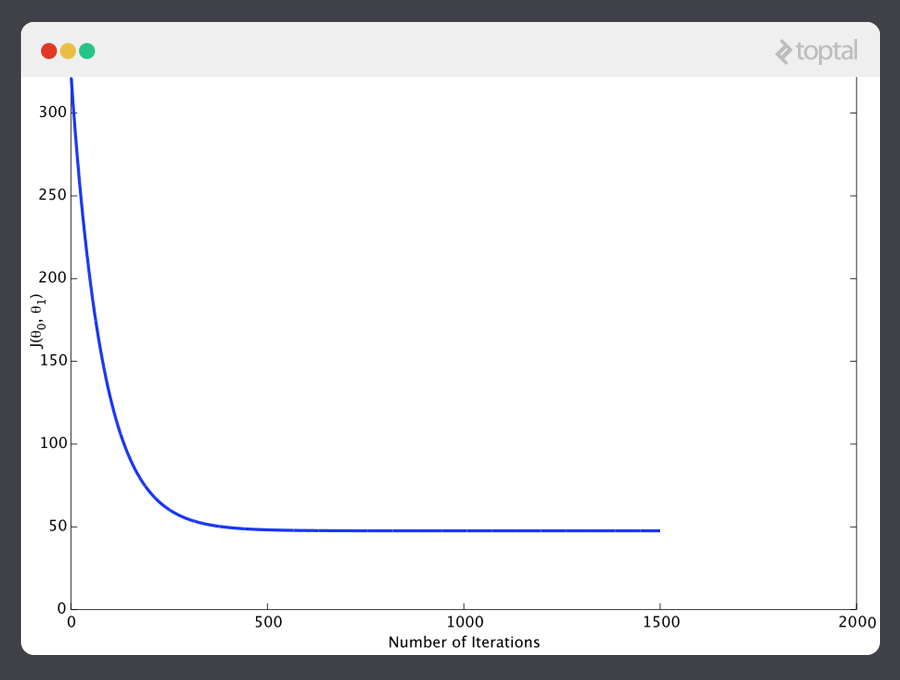
Esto abarca la teoría básica subyacente que representa la mayoría de los sistemas de Aprendizaje de Máquina supervisado. Pero los conceptos básicos pueden ser utilizados de diferentes formas dependiendo del problema.
Problemas de Clasificación
Del AM supervisado, existen dos sub-categorías importantes:
- Sistemas de Regresión de Aprendizaje de Máquina: Sistemas donde el valor que se predice está en algún lugar de un espectro continuo. Estos sistemas nos ayudan con preguntas tipo “¿Cuánto es?” o “¿Cuántos son?”.
- Sistemas de Clasificación de Aprendizaje de Máquina: Sistemas en los cuales se busca una predicción de sí-o-no, por ejemplo: “¿Este tumor es cancerígeno?”, “¿Esta galleta pasó nuestro estándar de calidad?” y preguntas por el estilo.
Y resulta que la teoría subyacente es más o menos igual. Las diferencias más grandes son el diseño del predictor h(x) y el diseño de la función de costo .
Nuestros ejemplos hasta ahora se han concentrado en problemas de regresión, así que ahora veamos un ejemplo de clasificación.
Aquí se muestran los resultados de un estudio de una prueba de calidad de una galleta, en el que los ejemplos de entrenamiento fueron etiquetados como “galleta buena” (y = 1) en azul o “galleta mala” (y = 0) en rojo.
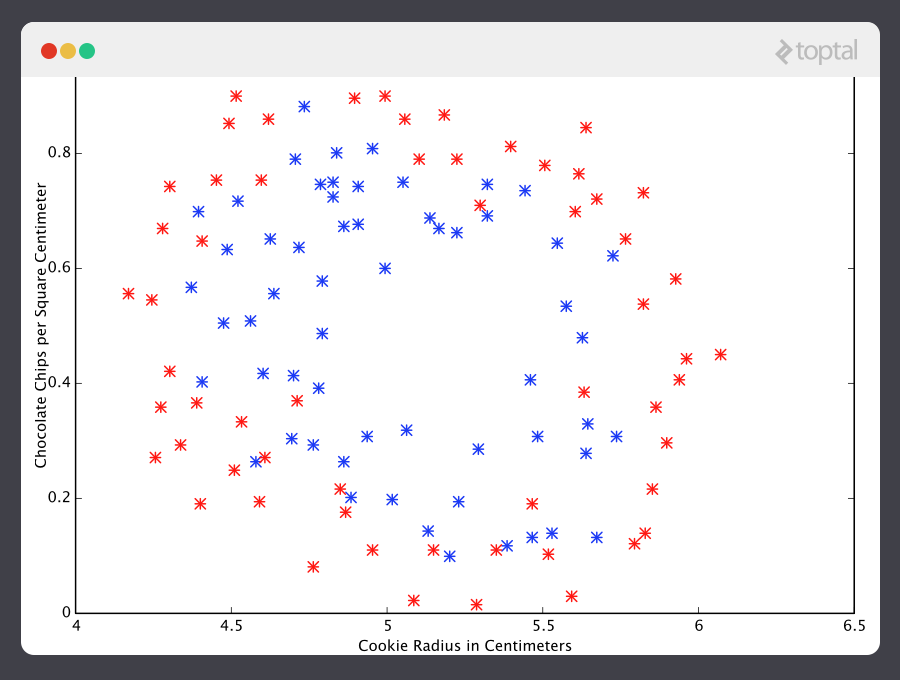
En clasificación, un predictor de regresión no es muy útil. Usualmente lo que queremos es un predictor que realice una suposición entre 0 y 1. En una clasificación de calidad de una galleta, una predicción de 1 representaría una suposición muy confiada de que la galleta es excelente y exquisitamente sabrosa. Una predicción de 0 representa una gran confianza de que la galleta es una vergüenza para la industria de las galletas. Los valores que se encuentran en este rango representan menos seguridad, por lo que podríamos diseñar nuestro sistema para que una predicción de 0.6 signifique “Oye, eso es una decisión difícil pero voy a decir que sí, sí puedes vender esa galleta,” mientras que un valor exactamente en el medio, 0.5, podría representar total incertidumbre. Esta no es siempre la forma en que la confianza se atribuye en un clasificador pero es un diseño bastante común y funciona para explicar nuestra ilustración.
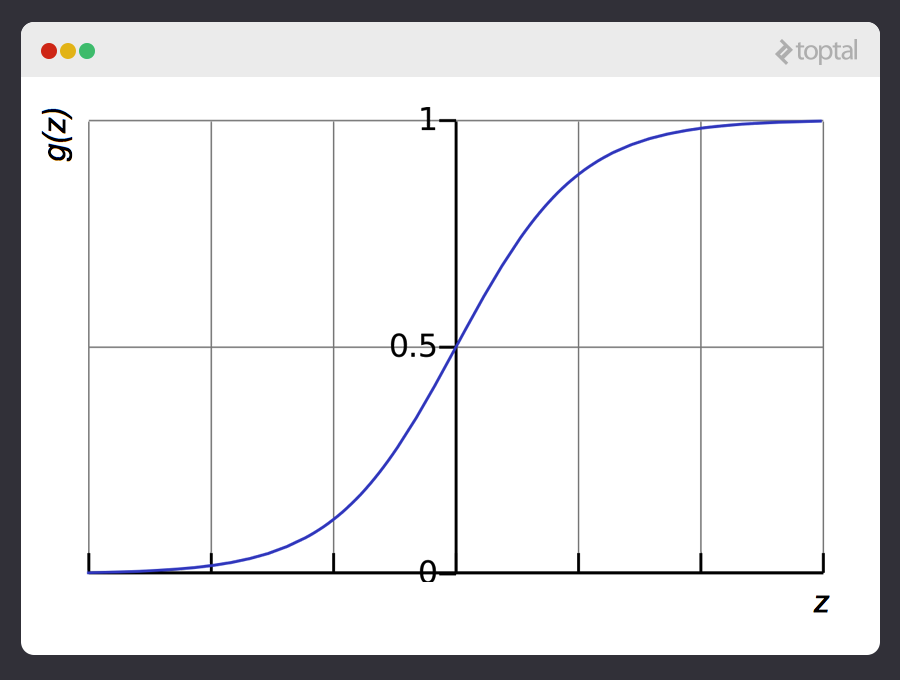
Hay una buena función que captura este comportamiento muy bien. Se llama la función sigmoide, g(z), y es algo así:
z es una representación de nuestros datos de entrada y coeficientes, tales como:
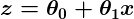
Así, nuestro predictor se convierte en:
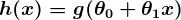
Puedes ver que la función sigmoide transforma nuestra salida a un rango entre 0 y 1.
La lógica del diseño de la función de costo también es diferente en la clasificación. Nuevamente preguntamos, ¿Qué significa que una suposición éste equivocada? Esta vez una muy buena regla del pulgar es que si la suposición correcta es 0 y nosotros dijimos 1, entonces estábamos completamente equivocados y viceversa. Y como no puedes estar más equivocado que la equivocación, la penalización en este caso es enorme. Ahora, si la suposición correcta fuera 0 y nosotros dijimos 0, nuestra función de costo no debería agregar ningún costo cada vez que esto pasa. Si la suposición fuera la correcta pero no estamos completamente seguros que sea así, (e.g. y = 1, but h(x) = 0.8), esto debería tener un pequeño costo y si nuestra suposición fuera incorrecta pero no estuviéramos seguros de ello (e.g. y = 1 but h(x) = 0.3), esto debería tener algún costo significativo pero no tanto como si estuviéramos completamente equivocados.
Este comportamiento es capturado por la función de registro de forma que:
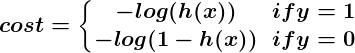
De nuevo, la función de costo nos da un promedio de costo sobre todos nuestros ejemplos de entrenamiento.
Y así aquí describimos como el predictor h(x) y la función de costo se diferencian en regresión y clasificación pero la descendencia de gradiente sigue funcionando igual.
Un pronosticador de clasificación se puede visualizar al dibujar la línea fronteriza; ej., la barrera donde la predicción cambia de un “si” (una predicción mayor a 0.5) a un “no” (una predicción menor a 0.5). Con un sistema bien diseñado, nuestra data de la galleta puede generar una frontera que se parece a esto:
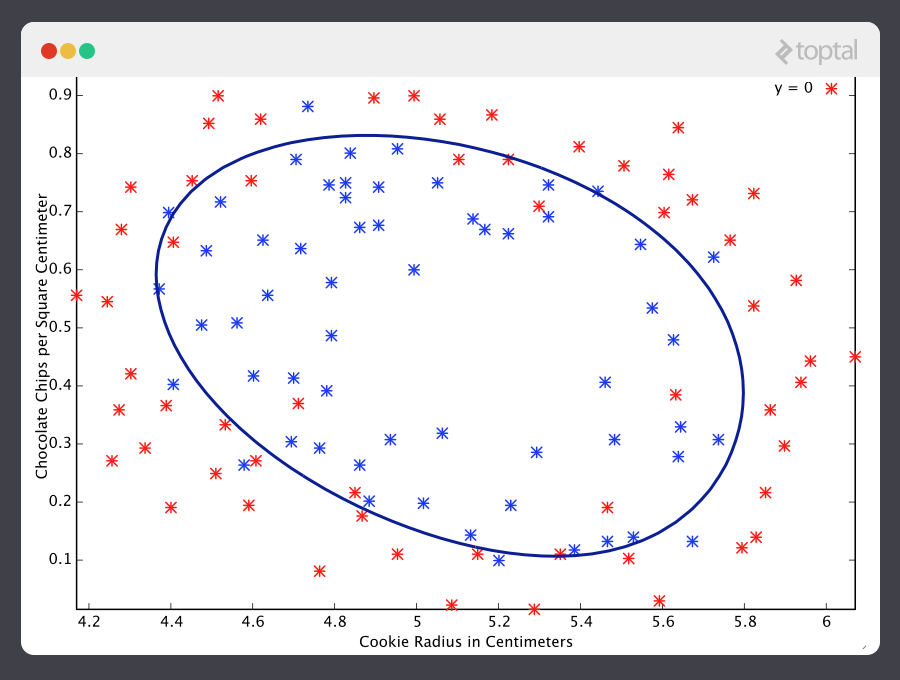
Ahora ¡esa es una máquina que conoce una cosa o dos sobre galletas!
Una Introducción a las Redes Neuronales
Ninguna discusión sobre AM estaría completa sin al menos mencionar las redes neuronales. Estas no solo ofrecen una herramienta extremadamente poderosa para resolver problemas difíciles pero también ofrecen pistas sobre cómo funcionan nuestros cerebros, al igual que intrigantes posibilidades para algún día crear máquinas inteligentes.
Las redes neuronales son excelentes para problemas de aprendizaje de máquina en los que las entradas son gigantes. El costo computacional de manejar dichos problemas es muy abrumador para los tipos de sistemas que hemos discutido arriba. Pero resulta que las redes neuronales pueden ser afinadas efectivamente usando técnicas que son sorprendentemente similares a la descendencia gradiente en principio.
Una discusión explicita sobre las redes neuronales va más allá de la información de este artículo, pero recomiendo revisar nuestro post anterior que trata el tema.
Aprendizaje de Máquina Sin Supervisión
Un aprendizaje sin supervisión, normalmente, se le asigna encontrar relaciones entre data. No hay ejemplos de entrenamiento usados en este proceso. En su lugar, se le da al sistema un set de data y se le asigna la tarea de buscar patrones y correlaciones dentro de éste. Un buen ejemplo es identificar grupos de amigos cercanos en data de redes sociales.
Los algoritmos usados para lograr esto, son muy distintos a aquellos usados para el aprendizaje supervisado y el tema amerita su propio artículo. Sin embargo, para tener algo mientras tanto, revisa [agrupamiento de algoritmos] (https://en.wikipedia.org/wiki/Cluster_analysis) como lo son k-means, y también revisa reducción de dimensionalidad sistemas como análisis de componente principal. Nuestro [post de gran data] (https://www.toptal.com/big-data#hiring-guide) discute un número de estos temas en más detalle.
Conclusión
Hemos cubierto mayor parte de la teoría básica subyacente al campo de Aprendizaje de Máquina pero, por supuesto, apenas hemos tocado la superficie.
Ten en mente que para aplicar las teorías presentes en esta introducción a ejemplos del aprendizaje de máquina de la vida real, es necesario una comprensión más profunda de los temas discutidos aquí. Hay muchas sutilezas y obstáculos en AM y muchas maneras de desviarse gracias a lo que parece ser una máquina de pensar bien afinada. Casi todas las partes de la teoría básica pueden ser alteradas o se puede jugar con ellas de muchas maneras y los resultados son, a menudo, fascinantes. Muchos se convierten en nuevos campos de estudio que corresponden mejor a un problema particular.
Claro está que el Aprendizaje de Máquina es una herramienta increíblemente poderosa. En los años venideros, promete ayudar a resolver algunos de nuestros problemas más inmediatos, al igual que abrir nuevos mundos de oportunidades. La demanda de ingenieros AM continuará creciendo y ofrecerá increíbles oportunidades de ser parte de algo especial. ¡Espero que consideres ser parte de la acción!
Artículo vía TopTal
Si te ha gustado este artículo únete a nuestro canal de Telegram o en Twitter.


